REGEX関数(REGEXEXTRACT・REGEXREPLACE・REGEXTEST)を使いこなす!Excelでの正規表現入門

Excelでデータを扱っていると、氏名の分割、住所からの都道府県抽出、メールアドレスの判定、電話番号の整形など、細かな文字列処理が日常的に発生します。LEFT・MID・SUBSTITUTE といった複数の関数を組み合わせれば対応できますが、数式が長くなり、管理も複雑になりがちです。
しかし、Microsoft 365 の Excel で 正規表現(RegEx) が利用できるようになったことで、こうした手間が大幅に軽減されました。文字列のルールをパターンとして指定できるため、複雑な条件でも短い式でシンプルに処理できます。特に REGEXEXTRACT(抽出)・REGEXREPLACE(置換)・REGEXTEST(判定) の3つを使いこなせば、これまで煩雑だった文字操作を驚くほど効率化できます。
この記事では、Excelでの正規表現の基礎と、実務で役立つ具体例を分かりやすく解説します。入門者でも理解しやすく、今日から業務に使える知識として身につけられます。
Excelで使えるREGEX関数とは?

Excelで使えるREGEX関数(正規表現関数)とは、正規表現という「文字列をパターンに沿って処理する仕組み」を、Excelのセル上で直接実行できるようにした関数です。
従来は複数の関数を組み合わせなければならなかった作業も、正規表現を使えばひとつのパターンで一括処理でき、データ整理の効率が大きく向上します。元々はエンジニア向けの技術でしたが、Excelに実装されたことで一般的な事務作業でも活用されるようになりました。
「難しそう」という印象に反して実用性は高く、大量データの整形やクリーニングでは、従来の関数では得られなかったスピードと正確さを発揮します。これが正規表現が注目される理由です。
正規表現関数の種類と特徴と対応バージョン
Excelの REGEX関数(正規表現関数)では次の処理が可能です。
- パターンに一致した部分を抽出
- 一致部分を別の文字列に置換
- 一致するかどうかをTRUE/FALSEで判定
どれも文字列処理に特化しており、従来は複雑だった操作を短い式で表現できます。
また、単体で便利なだけでなく、IF・TEXTAFTER・FILTER・LET など他の関数と組み合わせることで、より柔軟なデータ加工が実現します。
正規表現を特殊な道具として切り離すのではなく、文字列操作の共通ルールとして活用することで、Excel全体の表現力が一段階上がり、データ分析や帳票作成の質も向上します。
対応バージョン
正規表現関数に対応しているExcelは次のとおりです。
- Microsoft 365(デスクトップ版)
- Excel 2024
- Excel for the Web(Web版)
一方、永久ライセンスの旧版(Excel 2019 / 2021)は非対応です。
この違いを知らずに「使えない理由が分からない」という問い合わせも多いため、環境確認は必須です。利用環境によっては一部の関数が段階的にロールアウトされるケースもあり、職場やPCによって利用可否が異なることがあります。
関数名が「#NAME?」と表示される場合は、Excelの更新プログラムの適用やアカウント設定の確認で解決することが多い点も覚えておくと安心です。
よく使われる正規表現パターン一覧
正規表現を使いこなすうえで、頻出パターンを覚えておくと作業効率が大きく向上します。Excel での文字列処理でも特に利用頻度の高いものを、用途別に以下の表にまとめました。氏名・メール・住所・電話番号など、実務でよく扱うデータ整理の場面でそのまま活用できます。
| 用途 | 正規表現 |
|---|---|
| 0回以上の繰り返し | * |
| 1回以上の繰り返し | + |
| 0回か1回の繰り返し | ? |
| n回の繰り返し | {n} |
| 1文字以上の数字。 | [0-9]+ |
| 1文字以上の英字。 | [A-Za-z]+ |
| 空白(全角/半角) | \s |
| 空白以外の文字 | [^\s] |
| 「~で始まる」文字列 | ^ |
| 「~で終わる」文字列 | $ |
| 否定(~以外) | [^…] |
| 任意の1文字 | . |
| 電話番号(数字とハイフン) | [0-9\-]+ |
| メールアドレスの基本形 | [^@]+@.+ |
これらのパターンは REGEXEXTRACT・REGEXREPLACE・REGEXTEST で頻繁に用いられ、組み合わせることで実務のほとんどの文字列処理に対応できます。特に否定([^…])、先頭(^)、末尾($)は、短い式で高い精度の抽出を行う際の基本となるため、優先して覚えておくと便利です。
REGEXEXTRACT(抽出)の使い方と活用例

REGEXEXTRACTは、文字列の中から必要な部分だけを正規表現で取り出す関数です。氏名・メール・住所のように、位置が一定ではない情報でも、パターンに沿って抽出できるのが最大の特徴です。
REGEXEXTRACT関数は、文字列の中から「必要な部分だけを抜き出す」ために使用します。
| =REGEXEXTRACT(文字列,パターン(正規表現)) |
従来は複数の関数を組み合わせていた処理が格段にシンプルになります。抽出対象の位置が固定されていなくても対応できるため、名前・住所・メールなど「ルールはあるが位置が一定でない」文字列に非常に強いのが特徴です。
例1)氏名を「姓」と「名」に分割する

以下のように入力します。
- 姓:=REGEXEXTRACT(A2, “^[^\s]+”)
- ^[^\s]+ :先頭から空白以外の文字が続く部分=姓
- 名:=REGEXEXTRACT(A2, “(?<=\s).+”)
- (?<=\s).+:空白の直後から最後まで=名
全角・半角どちらのスペースにも対応でき、スペース位置に左右されず綺麗に分割できます。
例2)メールアドレスからユーザー名やドメインを抽出する
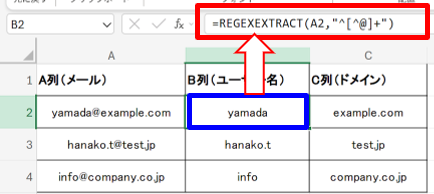
以下のように入力します。
- ユーザー名(@より前):=REGEXEXTRACT(A1, “^[^@]+”)
- ^[^@]+:先頭から@までの連続する文字
- ドメイン(@より後):=REGEXEXTRACT(A1, “(?<=@).+”)
- (?<=@) :… @の後に続く文字
部署ごとのドメイン抽出やログデータ整理など、メール情報の処理を簡潔に行えます。
例3)住所から都道府県名だけを抽出する

以下のように入力します。
- 都道府県パターン:=REGEXEXTRACT(A2, “東京都|北海道|京都府|大阪府|神奈川県”)
日本の住所形式に合わせたパターンを指定することで、先頭にある都道府県名を確実に抽出できます。住所正規化や入力チェックにも有効な処理です。
REGEXREPLACE(置換)の使い方と活用例

REGEXREPLACEは、文字列の特定部分を別の文字列に置き換えるための関数です。不要な文字の削除やフォーマットの整形など、データ品質をそろえる処理に最適です。
| =REGEXREPLACE(文字列,パターン(正規表現),置換後) |
不要な記号の除去、ハイフンの自動挿入、表記統一など、実務で頻出する処理に強く、特に大量データのフォーマットを一括調整したい場面で威力を発揮します。
例1)電話番号にハイフンを自動挿入

以下のように入力します。
- 整形:=REGEXREPLACE(A1, “(\d{3})(\d{4})(\d{4})”, “$1-$2-$3”)
- (\d{3})(\d{4})(\d{4}):3桁・4桁・4桁の数字
- $1-$2-$3:それぞれのグループをハイフンでつなぐ
入力のばらつきがある電話番号でも、瞬時に統一した形式へ整形できます。
例2)不要な文字や記号を削除
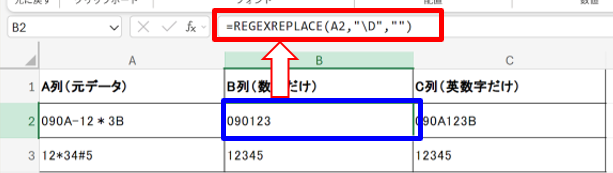
以下のように入力します。
- 数字以外をすべて削除:=REGEXREPLACE(A1, “\d”, “”)
- \d:半角数字
- 英数字以外を削除:=REGEXREPLACE(A1, “[^A-Za-z0-9]”, “”)
- [^A-Za-z0-9]:英大文字・小文字・数字以外の文字
名簿データや管理コードのクレンジングに非常に効果的です。
例3)特定文字列の統一表記
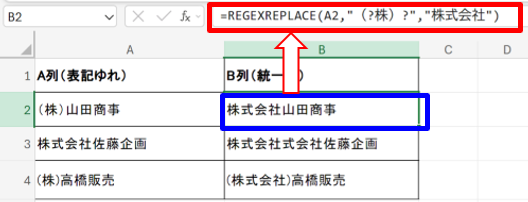
以下のように入力します。
- 「株式会社」「(株)」が混在しているデータを統一したい場合:=REGEXREPLACE(A1, “(?株)?”, “株式会社”)
- (?株)?:「株」または「(株)」
「株式会社」「(株)」が混在している企業名データでも、簡単に表記を揃えられます。表記揺れを整えるだけで、データの品質向上につながります。
REGEXTEST(判定)の使い方と活用例

REGEXTESTは、「この文字列が条件に一致しているかどうか」を判定する関数です。
結果は TRUE / FALSE で返されるため、IF関数と組み合わせた入力チェックやデータ品質管理で効果を発揮します。
| =REGEXTEST(文字列,パターン(正規表現)) |
判定結果をそのまま条件分岐に使えるため、入力フォームのチェックの自動化や誤入力防止に役立ちます。
例1)メールアドレス形式チェック
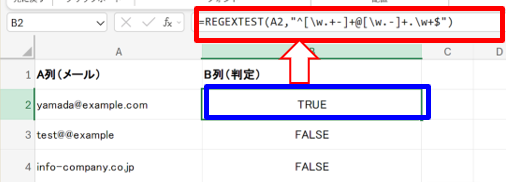
以下のように入力します。
- 判定結果を記載する欄:=REGEXTEST(A1, “^[\w.+-]+@[\w.-]+\.\w+$”)
- ^[\w.+-]+@[\w.-]+\.\w+$:○○@○○.○○のメールアドレス形式
名簿登録やフォーム入力の精度確認に活用できます。
例2)数字のみ判定
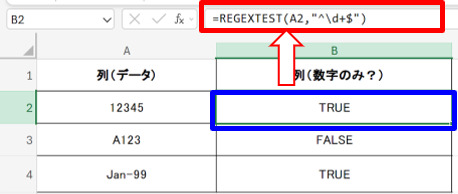
以下のように入力します。
- 判定結果を記載する欄:=REGEXTEST(A1, “^\d+$”)
- ^\d+$:文字の先頭から末尾まで数字のみ
管理番号や商品コードの誤入力確認に便利です。
例3)電話番号ハイフン判定
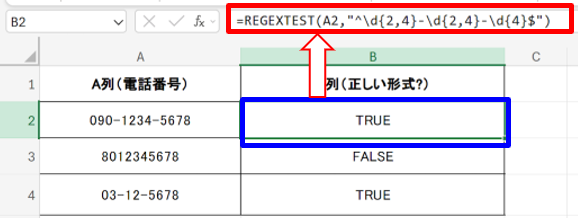
以下のように入力します。
- 判定結果を記載する欄:=REGEXTEST(A1, “^\d{2,4}-\d{2,4}-\d{4}$”)
- ^\d{2,4}-\d{2,4}-\d{4}$:日本の電話番号形式(XX-XXXX-XXXXなど)
表記揺れがある電話番号を簡単に識別でき、データ精度が向上します。
まとめ
Excelに正規表現機能が追加されたことで、文字列処理は格段に効率化されました。
特にREGEXEXTRACT・REGEXREPLACE・REGEXTESTの3つを理解すれば、抽出・置換・判定の大半を短いパターンで表現でき、作業時間を大きく短縮できます。
名前の分割、住所の抽出、電話番号の整形、メール形式チェックなど、日常業務でよく発生する処理と相性が良く、Microsoft 365 や Excel 2024 を利用しているユーザーにとってぜひ習得しておきたいスキルです。
正規表現は慣れるほど強力なツールになります。まずはこの記事の例を実際に入力し、操作に慣れていくことをおすすめします。データ加工のスピードと正確性が大きく向上することを実感できるはずです。